class: inverse, bottom background-image: url(https://images.unsplash.com/photo-1532012197267-da84d127e765?q=80&w=1587&auto=format&fit=crop&ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D) background-size: cover # .Large[flipbooks] ## .small[past, present, future] ## .small[bit.ly/flipbooks-llnl] #### .tiny[Dr. Evangeline Reynolds | 2023-11-16 | Lawrence Livermore National Lab R Users Meetup , Image credit: Jaredd Craig, Upsplash] ??? --- class: center, middle, inverse # flipbooks: An unfolding tale about empathy via pairing... -- draft manuscript: https://github.com/EvaMaeRey/flipbookr/blob/master/docs/draft_jasa_submission.pdf --- class: inverse # Abstract: -- Flipbooks reveal code pipe-lines -- line-by-line -- and side-by-side with output, -- which yields an animated experience. --- count: false ## A code 'flipbook' .panel1-scatter-auto[ ```r *library(ggplot2) ``` ] .panel2-scatter-auto[ ] --- count: false ## A code 'flipbook' .panel1-scatter-auto[ ```r library(ggplot2) *gapminder::gapminder ``` ] .panel2-scatter-auto[ ``` ## # A tibble: 1,704 × 6 ## country continent year lifeExp pop gdpPercap ## <fct> <fct> <int> <dbl> <int> <dbl> ## 1 Afghanistan Asia 1952 28.8 8425333 779. ## 2 Afghanistan Asia 1957 30.3 9240934 821. ## 3 Afghanistan Asia 1962 32.0 10267083 853. ## 4 Afghanistan Asia 1967 34.0 11537966 836. ## 5 Afghanistan Asia 1972 36.1 13079460 740. ## 6 Afghanistan Asia 1977 38.4 14880372 786. ## 7 Afghanistan Asia 1982 39.9 12881816 978. ## 8 Afghanistan Asia 1987 40.8 13867957 852. ## 9 Afghanistan Asia 1992 41.7 16317921 649. ## 10 Afghanistan Asia 1997 41.8 22227415 635. ## # ℹ 1,694 more rows ``` ] --- count: false ## A code 'flipbook' .panel1-scatter-auto[ ```r library(ggplot2) gapminder::gapminder %>% * dplyr::filter(year == 2002) ``` ] .panel2-scatter-auto[ ``` ## # A tibble: 142 × 6 ## country continent year lifeExp pop gdpPercap ## <fct> <fct> <int> <dbl> <int> <dbl> ## 1 Afghanistan Asia 2002 42.1 25268405 727. ## 2 Albania Europe 2002 75.7 3508512 4604. ## 3 Algeria Africa 2002 71.0 31287142 5288. ## 4 Angola Africa 2002 41.0 10866106 2773. ## 5 Argentina Americas 2002 74.3 38331121 8798. ## 6 Australia Oceania 2002 80.4 19546792 30688. ## 7 Austria Europe 2002 79.0 8148312 32418. ## 8 Bahrain Asia 2002 74.8 656397 23404. ## 9 Bangladesh Asia 2002 62.0 135656790 1136. ## 10 Belgium Europe 2002 78.3 10311970 30486. ## # ℹ 132 more rows ``` ] --- count: false ## A code 'flipbook' .panel1-scatter-auto[ ```r library(ggplot2) gapminder::gapminder %>% dplyr::filter(year == 2002) %>% * ggplot() ``` ] .panel2-scatter-auto[ <!-- --> ] --- count: false ## A code 'flipbook' .panel1-scatter-auto[ ```r library(ggplot2) gapminder::gapminder %>% dplyr::filter(year == 2002) %>% ggplot() + * aes(y = lifeExp) ``` ] .panel2-scatter-auto[ <!-- --> ] --- count: false ## A code 'flipbook' .panel1-scatter-auto[ ```r library(ggplot2) gapminder::gapminder %>% dplyr::filter(year == 2002) %>% ggplot() + aes(y = lifeExp) + * aes(x = gdpPercap) ``` ] .panel2-scatter-auto[ <!-- --> ] --- count: false ## A code 'flipbook' .panel1-scatter-auto[ ```r library(ggplot2) gapminder::gapminder %>% dplyr::filter(year == 2002) %>% ggplot() + aes(y = lifeExp) + aes(x = gdpPercap) + * geom_point() ``` ] .panel2-scatter-auto[ <!-- --> ] --- count: false ## A code 'flipbook' .panel1-scatter-auto[ ```r library(ggplot2) gapminder::gapminder %>% dplyr::filter(year == 2002) %>% ggplot() + aes(y = lifeExp) + aes(x = gdpPercap) + geom_point() + * aes(size = pop/1000000000) ``` ] .panel2-scatter-auto[ <!-- --> ] --- count: false ## A code 'flipbook' .panel1-scatter-auto[ ```r library(ggplot2) gapminder::gapminder %>% dplyr::filter(year == 2002) %>% ggplot() + aes(y = lifeExp) + aes(x = gdpPercap) + geom_point() + aes(size = pop/1000000000) + * aes(color = continent) ``` ] .panel2-scatter-auto[ <!-- --> ] <style> .panel1-scatter-auto { color: black; width: 38.6060606060606%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel2-scatter-auto { color: black; width: 59.3939393939394%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel3-scatter-auto { color: black; width: NA%; hight: 33%; float: left; padding-left: 1%; font-size: 80% } </style> <!-- --- --> <!-- ### This movie magic arises, because code and output are revealed in a slide show, and content is aligned from one slide to another, which makes differencing (seeing what's new) a effortless physiological process rather than a cognitive one (the case of visual search), availing more cognitive resources to task of interpretation of how code and output pair. --> <!-- --- --> <!-- ### Flipbooks are additionally powerful, because users can move at their own pace, and back and forth to help address their own specific doubts. The implementation allows users to copy and paste code, full pipelines or bits relevant to their problems. Highlighting newest code in a pipeline allows the consumer to focus on what's changing in the output space, rather than th --> <!-- --- --> <!-- ### Yet, flipbook *making* has been somewhat cumbersome (does not feel magical), requiring *detailed* know-how about tools like the knitr dynamic document system, YAMLs, and Xaringan. And their use has primarily been by educators creating material for students, in workshops, and presentations. --> <!-- --- --> <!-- ### New efforts to create `chunk_reveal_live` might put this tech in the hands of more coding newcomers; including on-the-fly classroom use. Arguably the people that might find flipbooks the most useful (people who aren't going to be able to 'just-read' a pipeline of code), might find them even more engaging when they are used to review and present on the most interesting pipelines: their own explorations of their own data. --> --- # Talk outline ## Chapter 1: *Pairing* code and independent plot elements is elegant, and *empathetic* (Lelend Wilkinson, Hadley Wickham) -- ## Chapter 2: step-by-step code-output reveal (*focused pairing*) is gentle and *empathetic* (Garrick Aden-Bui, others) --- ## Backstory Chapter 3.0: Explaining your plot bit by bit makes your presentation stronger, because it is *empathetic* (Matt Blackwell; Hans Rosling) (*narrative with graphical-element pairing*) -- ## Chapter 3: Sequential reveal allows for *automating paired* reveal, which is *self-empathetic* (Me; Emi Tanaka; Garrick Aden-Bui) --- ## Chapter 4: {flipbookr} package is born. --- ## Next Chapter: chunk_reveal_live()... Making flipbook making more accessible is *empathetic.* (via Kelly Bodwin; rstudioapi; Me) <!-- ### also faster feedback for iterative design process. --> --- ## Yet another Chapter: Flipbookr for quarto: Keeping it up-to-date is empathetic (Kieran Healey; Kelly Bodwin; me?) --- # Chapter 1: *pairing* code with plot element is elegant and *empathetic*... --- ## Leland Wilkinson's Grammar of Graphics work kind of discover the 'natural language' of chart definition. -- ## different gg implementations (Tableau, spss' etc) allow us great ability to express ourselves! --- ## Leland Wilkinson identified orthogonal elements in 'The Grammar of Graphics'. Wilkinson on the Policy Viz Podcast [here](https://policyviz.com/podcast/episode-201-leland-wilkinson/). <img src="https://miro.medium.com/max/1400/1*MMZuYgeC_YjXNC1r4D4sog.png" width="75%" /> --- ## But unlike natural languages, Japanese, English, Dutch... there wasn't anything *freely* available! -- ## Hadley Wickam reading the grammar of graphics, paraphrase: 'This is so beautiful, ... but there's no software." --- ### Hadley Wickham, ggplot2 author on it's motivation: > ### And, you know, I'd get a dataset. And, *in my head I could very clearly kind of picture*, I want to put this on the x-axis. Let's put this on the y-axis, draw a line, put some points here, break it up by this variable. -- > ### And then, like, getting that vision out of my head, and into reality, it's just really, really hard. Just, like, felt harder than it should be. Like, there's a lot of custom programming involved, --- > ### where I just felt, like, to me, I just wanted to say, like, you know, *this is what I'm thinking, this is how I'm picturing this plot. Like you're the computer 'Go and do it'.* -- > ### ... and I'd also been reading about the Grammar of Graphics by Leland Wilkinson, I got to meet him a couple of times and ... I was, like, this book has been, like, written for me. https://www.trifacta.com/podcast/tidy-data-with-hadley-wickham/ --- # ggplot2 let us "... create graphical 'poems'." - Hadley Wickham (2010) in 'A Layered Grammar of Graphics', *Journal of Computational and Graphical Statistics* --- count: false ## ggplot2 code is a sussinct graphical narrative, where the orthogonal components may independently declared ```r *library(ggplot2) ``` --- count: false ## ggplot2 code is a sussinct graphical narrative, where the orthogonal components may independently declared ```r library(ggplot2) *ggplot(data = gapminder_2002) ``` --- count: false ## ggplot2 code is a sussinct graphical narrative, where the orthogonal components may independently declared ```r library(ggplot2) ggplot(data = gapminder_2002) + * aes(y = lifeExp) ``` --- count: false ## ggplot2 code is a sussinct graphical narrative, where the orthogonal components may independently declared ```r library(ggplot2) ggplot(data = gapminder_2002) + aes(y = lifeExp) + * aes(x = gdpPercap) ``` --- count: false ## ggplot2 code is a sussinct graphical narrative, where the orthogonal components may independently declared ```r library(ggplot2) ggplot(data = gapminder_2002) + aes(y = lifeExp) + aes(x = gdpPercap) + * geom_point() ``` --- count: false ## ggplot2 code is a sussinct graphical narrative, where the orthogonal components may independently declared ```r library(ggplot2) ggplot(data = gapminder_2002) + aes(y = lifeExp) + aes(x = gdpPercap) + geom_point() + * aes(size = pop/1000000000) ``` --- count: false ## ggplot2 code is a sussinct graphical narrative, where the orthogonal components may independently declared ```r library(ggplot2) ggplot(data = gapminder_2002) + aes(y = lifeExp) + aes(x = gdpPercap) + geom_point() + aes(size = pop/1000000000) + * aes(color = continent) ``` <style> .panel1-scatter2-auto { color: black; width: 99%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel2-scatter2-auto { color: black; width: NA%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel3-scatter2-auto { color: black; width: NA%; hight: 33%; float: left; padding-left: 1%; font-size: 80% } </style> --- # 'Here's what I have in my head, I'm going to translate that to a grammatical representation.' --- class: inverse, center, middle > # "the Grammar of Graphics makes [building plots] easy because you've just got all these, like, little nice *decomposible components*" -- Hadley Wickham ### They actually map pretty well to how you might go about describing the sketch of the data visualization as you sketch it out. --- # Chapter 2: *showing* pairing by *coodinated reveal* is gentle and empathetic (Garrick Aden-Bui, others) https://pkg.garrickadenbuie.com/gentle-ggplot2/#1 --- <blockquote class="twitter-tweet"><p lang="en" dir="ltr">Really dig how <a href="https://twitter.com/grrrck?ref_src=twsrc%5Etfw">@grrrck</a> builds up <a href="https://twitter.com/hashtag/ggplot2?src=hash&ref_src=twsrc%5Etfw">#ggplot2</a> syntax w/ 📊:<br>📽 "A Gentle Guide to the Grammar of Graphics with ggplot2" <a href="https://t.co/2Okhri7Hox">https://t.co/2Okhri7Hox</a> <a href="https://twitter.com/hashtag/rstats?src=hash&ref_src=twsrc%5Etfw">#rstats</a> <a href="https://twitter.com/hashtag/dataviz?src=hash&ref_src=twsrc%5Etfw">#dataviz</a> <a href="https://t.co/qO43IeTtHG">pic.twitter.com/qO43IeTtHG</a></p>— Mara Averick (@dataandme) <a href="https://twitter.com/dataandme/status/995650384155693061?ref_src=twsrc%5Etfw">May 13, 2018</a></blockquote> <script async src="https://platform.twitter.com/widgets.js" charset="utf-8"></script> --- ## True to some of natural language aquisition... Point to each thing and name it... (as happens in real-time demos or *pair* programming too.) -- ## ggplot2 lets you 'speaking your plot into existence'; write 'graphical poems' -- ## Garrick read the poem out loud (poetry slam!): Bedtime story, picture book version, where parent is pointing out new vocabulary as the she reads the book. --- # Back Story for Chapter 3. ### Origins in presentation and *empathy* for your audience in presentation that *pairs* a narrative with plot element reveal. <blockquote class="twitter-tweet"><p lang="en" dir="ltr">My best tip on how to give better quantitative presentations is to (a) use more plots and (b) build up your plots on multiple overlays, as in:<br><br>- Just x-axis (explain it)<br>- Add y-axis (explain it)<br>- Add 1 data point (explain it)<br>- Plot the rest of the data (explain it)</p>— Matt Blackwell (@matt_blackwell) <a href="https://twitter.com/matt_blackwell/status/991004129198854145?ref_src=twsrc%5Etfw">April 30, 2018</a></blockquote> <script async src="https://platform.twitter.com/widgets.js" charset="utf-8"></script> --- ## you are practicing empathy by using data visualization (it's fast); gonna make seeing patterns in your data feel effortless -- ## Visual information channels are "preattentively processed" -- Cleveland and McGill 1984 ## "preattentively processed" == effortlessness --- ### but you can encode so much in a data viz... <img src="https://clauswilke.com/dataviz/aesthetic_mapping_files/figure-html/common-aesthetics-1.png" width="80%" /> Wilke's Fundamentals of data visualization -- ### ...So you really need to talk about *each* encoding (one by one) or the interpretation is lost. -- i.e. each visual channel-variable *pair* --- # And when people do, this it is really appreciated... Hans Rosling & BBC in 2010 <iframe width="767" height="431" src="https://www.youtube.com/embed/jbkSRLYSojo?list=PL6F8D7054D12E7C5A" frameborder="0" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe> https://www.youtube.com/embed/jbkSRLYSojo?list=PL6F8D7054D12E7C5A --- # 'Here we go. Life expectancy on the y-axis' <img src="images/hans_y_axis.png" width="80%" /> --- # 'On the x-axis, wealth' <img src="images/hans_x_axis.png" width="80%" /> --- # 'Colors represent the different continents' <img src="images/hans_colors.png" width="80%" /> --- # 'Size represents population' <img src="images/hans_size.png" width="80%" /> --- class: inverse, center, middle # Response to empathic presentation? -- # 10 million views... -- (also does animation at the end... which I don't show... I think this kind of distracts from the other reasons this presentation is so great.) --- # Chapter 3. Sequential reveal and automation ## Not me at the time: 'Wow, that is profoundly empathetic'. 🦉🦉🦉 -- ## Me at the time: 'Neat-o! That sounds a lot like the *layered* presentation of graphics.' 🤓🤓🤓 --- <blockquote class="twitter-tweet"><p lang="en" dir="ltr">Good ideas! Very <a href="https://twitter.com/hashtag/ggplot?src=hash&ref_src=twsrc%5Etfw">#ggplot</a>. A layered presentation of graphics. <a href="https://t.co/M4tRB9bGS5">https://t.co/M4tRB9bGS5</a></p>— Gina Reynolds (@EvaMaeRey) <a href="https://twitter.com/EvaMaeRey/status/991269331257487366?ref_src=twsrc%5Etfw">May 1, 2018</a></blockquote> <script async src="https://platform.twitter.com/widgets.js" charset="utf-8"></script> --- <blockquote class="twitter-tweet"><p lang="en" dir="ltr">Here, building up a <a href="https://twitter.com/hashtag/ggplot2?src=hash&ref_src=twsrc%5Etfw">#ggplot2</a> as slowly as possible, <a href="https://twitter.com/hashtag/rstats?src=hash&ref_src=twsrc%5Etfw">#rstats</a>. Incremental adjustments. <a href="https://twitter.com/hashtag/rstatsteachingideas?src=hash&ref_src=twsrc%5Etfw">#rstatsteachingideas</a> <a href="https://t.co/nUulQl8bPh">pic.twitter.com/nUulQl8bPh</a></p>— Gina Reynolds (@EvaMaeRey) <a href="https://twitter.com/EvaMaeRey/status/1029104656763572226?ref_src=twsrc%5Etfw">August 13, 2018</a></blockquote> <script async src="https://platform.twitter.com/widgets.js" charset="utf-8"></script> --- ## Emi Tanaka; Semi-automation... <blockquote class="twitter-tweet"><p lang="en" dir="ltr">Inspired by <a href="https://twitter.com/grrrck?ref_src=twsrc%5Etfw">@grrrck</a> and <a href="https://twitter.com/EvaMaeRey?ref_src=twsrc%5Etfw">@EvaMaeRey</a>, made the kunoichi + ninjutsu (ninja-theme) version of <a href="https://twitter.com/hashtag/ggplot?src=hash&ref_src=twsrc%5Etfw">#ggplot</a> tutorial although Garrick already does explaining this in his excellent blog <a href="https://t.co/msXfg14Ztn">https://t.co/msXfg14Ztn</a>. Gist for ninja-theme here: <a href="https://t.co/soHH4Qvz4F">https://t.co/soHH4Qvz4F</a> <a href="https://twitter.com/hashtag/rstats?src=hash&ref_src=twsrc%5Etfw">#rstats</a> <a href="https://t.co/YlRHAGnaUm">pic.twitter.com/YlRHAGnaUm</a></p>— Emi Tanaka @emitanaka@fosstodon.org (@statsgen) <a href="https://twitter.com/statsgen/status/1041279648452108289?ref_src=twsrc%5Etfw">September 16, 2018</a></blockquote> <script async src="https://platform.twitter.com/widgets.js" charset="utf-8"></script> --- count: false ### Unpaired pipeline_steps & graphical_elements ``` ## # A tibble: 1 × 2 ## function_name gg_element ## <chr> <chr> ## 1 ggplot2 func 'A' grammar move # 1 ``` --- count: false ### Unpaired pipeline_steps & graphical_elements ``` ## # A tibble: 2 × 2 ## function_name gg_element ## <chr> <chr> ## 1 ggplot2 func 'A' grammar move # 1 ## 2 ggplot2 func 'B' grammar move # 2 ``` --- count: false ### Unpaired pipeline_steps & graphical_elements ``` ## # A tibble: 3 × 2 ## function_name gg_element ## <chr> <chr> ## 1 ggplot2 func 'A' grammar move # 1 ## 2 ggplot2 func 'B' grammar move # 2 ## 3 ggplot2 func 'C' grammar move # 3 ``` --- count: false ### Unpaired pipeline_steps & graphical_elements ``` ## # A tibble: 4 × 2 ## function_name gg_element ## <chr> <chr> ## 1 ggplot2 func 'A' grammar move # 1 ## 2 ggplot2 func 'B' grammar move # 2 ## 3 ggplot2 func 'C' grammar move # 3 ## 4 ggplot2 func 'D' grammar move # 4 ``` --- count: false ### Unpaired pipeline_steps & graphical_elements ``` ## # A tibble: 5 × 2 ## function_name gg_element ## <chr> <chr> ## 1 ggplot2 func 'A' grammar move # 1 ## 2 ggplot2 func 'B' grammar move # 2 ## 3 ggplot2 func 'C' grammar move # 3 ## 4 ggplot2 func 'D' grammar move # 4 ## 5 ggplot2 func 'E' grammar move # 5 ``` --- count: false ### Unpaired pipeline_steps & graphical_elements ``` ## # A tibble: 6 × 2 ## function_name gg_element ## <chr> <chr> ## 1 ggplot2 func 'A' grammar move # 1 ## 2 ggplot2 func 'B' grammar move # 2 ## 3 ggplot2 func 'C' grammar move # 3 ## 4 ggplot2 func 'D' grammar move # 4 ## 5 ggplot2 func 'E' grammar move # 5 ## 6 ggplot2 func 'F' grammar move # 6 ``` --- count: false ### Unpaired pipeline_steps & graphical_elements ``` ## # A tibble: 7 × 2 ## function_name gg_element ## <chr> <chr> ## 1 ggplot2 func 'A' grammar move # 1 ## 2 ggplot2 func 'B' grammar move # 2 ## 3 ggplot2 func 'C' grammar move # 3 ## 4 ggplot2 func 'D' grammar move # 4 ## 5 ggplot2 func 'E' grammar move # 5 ## 6 ggplot2 func 'F' grammar move # 6 ## 7 ggplot2 func 'G' grammar move # 7 ``` --- count: false ### Unpaired pipeline_steps & graphical_elements ``` ## # A tibble: 8 × 2 ## function_name gg_element ## <chr> <chr> ## 1 ggplot2 func 'A' grammar move # 1 ## 2 ggplot2 func 'B' grammar move # 2 ## 3 ggplot2 func 'C' grammar move # 3 ## 4 ggplot2 func 'D' grammar move # 4 ## 5 ggplot2 func 'E' grammar move # 5 ## 6 ggplot2 func 'F' grammar move # 6 ## 7 ggplot2 func 'G' grammar move # 7 ## 8 ggplot2 func 'H' grammar move # 8 ``` --- count: false ### Unpaired pipeline_steps & graphical_elements ``` ## # A tibble: 9 × 2 ## function_name gg_element ## <chr> <chr> ## 1 ggplot2 func 'A' grammar move # 1 ## 2 ggplot2 func 'B' grammar move # 2 ## 3 ggplot2 func 'C' grammar move # 3 ## 4 ggplot2 func 'D' grammar move # 4 ## 5 ggplot2 func 'E' grammar move # 5 ## 6 ggplot2 func 'F' grammar move # 6 ## 7 ggplot2 func 'G' grammar move # 7 ## 8 ggplot2 func 'H' grammar move # 8 ## 9 ggplot2 func 'I' grammar move # 9 ``` <style> .panel1-pairing-replace { color: black; width: 99%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel2-pairing-replace { color: black; width: NA%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel3-pairing-replace { color: black; width: NA%; hight: 33%; float: left; padding-left: 1%; font-size: 80% } </style> --- ### Usual code-output pairing? (pairing at all is empathetic! output helps communicat intent of code. Afforeded by dynamic document systems: knitr, quarto, jupytr notebooks.) -- #### Complete code pipeline ```r library(ggplot2) gapminder::gapminder %>% dplyr::filter(year == 2002) %>% ggplot() + aes(y = lifeExp) + aes(x = gdpPercap) + geom_point() + aes(size = pop/1000000000) + aes(color = continent) ``` -- #### Complete plot <img src="flipbooks-lawrence-livermore_files/figure-html/unnamed-chunk-9-1.png" height="10%" /> --- ### Possible pairings of functions and gg graphical moves. <!-- --> # flipbook pairing is 'tidy', like vectors organized in a data frame... --- count: false ## One more example of familiar powerful *pairing*, 'tidy data'; e.g. data frames ### How many Minnies in 1880? .panel1-babynamesvectors-auto[ ```r *babynames::babynames$name[1:10] ``` ] .panel2-babynamesvectors-auto[ ``` ## [1] "Mary" "Anna" "Emma" "Elizabeth" "Minnie" "Margaret" ## [7] "Ida" "Alice" "Bertha" "Sarah" ``` ] --- count: false ## One more example of familiar powerful *pairing*, 'tidy data'; e.g. data frames ### How many Minnies in 1880? .panel1-babynamesvectors-auto[ ```r babynames::babynames$name[1:10] *babynames::babynames$n[1:10] ``` ] .panel2-babynamesvectors-auto[ ``` ## [1] "Mary" "Anna" "Emma" "Elizabeth" "Minnie" "Margaret" ## [7] "Ida" "Alice" "Bertha" "Sarah" ``` ``` ## [1] 7065 2604 2003 1939 1746 1578 1472 1414 1320 1288 ``` ] --- count: false ## One more example of familiar powerful *pairing*, 'tidy data'; e.g. data frames ### How many Minnies in 1880? .panel1-babynamesvectors-auto[ ```r babynames::babynames$name[1:10] babynames::babynames$n[1:10] *babynames::babynames$year[1:10] ``` ] .panel2-babynamesvectors-auto[ ``` ## [1] "Mary" "Anna" "Emma" "Elizabeth" "Minnie" "Margaret" ## [7] "Ida" "Alice" "Bertha" "Sarah" ``` ``` ## [1] 7065 2604 2003 1939 1746 1578 1472 1414 1320 1288 ``` ``` ## [1] 1880 1880 1880 1880 1880 1880 1880 1880 1880 1880 ``` ] --- count: false ## One more example of familiar powerful *pairing*, 'tidy data'; e.g. data frames ### How many Minnies in 1880? .panel1-babynamesvectors-auto[ ```r babynames::babynames$name[1:10] babynames::babynames$n[1:10] babynames::babynames$year[1:10] # better when paired... *babynames::babynames %>% select(name, year, n) %>% .[1:10,] ``` ] .panel2-babynamesvectors-auto[ ``` ## [1] "Mary" "Anna" "Emma" "Elizabeth" "Minnie" "Margaret" ## [7] "Ida" "Alice" "Bertha" "Sarah" ``` ``` ## [1] 7065 2604 2003 1939 1746 1578 1472 1414 1320 1288 ``` ``` ## [1] 1880 1880 1880 1880 1880 1880 1880 1880 1880 1880 ``` ``` ## # A tibble: 10 × 3 ## name year n ## <chr> <dbl> <int> ## 1 Mary 1880 7065 ## 2 Anna 1880 2604 ## 3 Emma 1880 2003 ## 4 Elizabeth 1880 1939 ## 5 Minnie 1880 1746 ## 6 Margaret 1880 1578 ## 7 Ida 1880 1472 ## 8 Alice 1880 1414 ## 9 Bertha 1880 1320 ## 10 Sarah 1880 1288 ``` ] --- count: false ## One more example of familiar powerful *pairing*, 'tidy data'; e.g. data frames ### How many Minnies in 1880? .panel1-babynamesvectors-auto[ ```r babynames::babynames$name[1:10] babynames::babynames$n[1:10] babynames::babynames$year[1:10] # better when paired... babynames::babynames %>% select(name, year, n) %>% .[1:10,] ``` ] .panel2-babynamesvectors-auto[ ``` ## [1] "Mary" "Anna" "Emma" "Elizabeth" "Minnie" "Margaret" ## [7] "Ida" "Alice" "Bertha" "Sarah" ``` ``` ## [1] 7065 2604 2003 1939 1746 1578 1472 1414 1320 1288 ``` ``` ## [1] 1880 1880 1880 1880 1880 1880 1880 1880 1880 1880 ``` ``` ## # A tibble: 10 × 3 ## name year n ## <chr> <dbl> <int> ## 1 Mary 1880 7065 ## 2 Anna 1880 2604 ## 3 Emma 1880 2003 ## 4 Elizabeth 1880 1939 ## 5 Minnie 1880 1746 ## 6 Margaret 1880 1578 ## 7 Ida 1880 1472 ## 8 Alice 1880 1414 ## 9 Bertha 1880 1320 ## 10 Sarah 1880 1288 ``` ] <style> .panel1-babynamesvectors-auto { color: black; width: 38.6060606060606%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel2-babynamesvectors-auto { color: black; width: 59.3939393939394%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel3-babynamesvectors-auto { color: black; width: NA%; hight: 33%; float: left; padding-left: 1%; font-size: 80% } </style> When variables come at us one by one, answering Minnies in 1880 is hard; when paired, answering the question is easy. --- ### {flipbookr} was born ```r remotes::install.github("EvaMaeRey/flipbookr") install.packages("xaringan") ``` ### RConsortium Grant. Thanks! --- # Live demo - with flipbookr ```r install.packages("xaringan") remotes::install_github("EvaMaeRey/flipbookr") ``` ## RStudio -> File -> New File -> R Markdown -> From Template -> Template: A Minimal Flipbook --- # In the backgroud flipbookr::chunk_reveal(): -- ## grabs code from chunk, -- parses it, -- explodes it into partial builds, -- inserts each partial build into individual slides for presentation in Xaringan --- # Flipbooks should feel a little *magical...* -- # {flipbookr} makes creating a flipbook is *manigeable*, -- but we're not quite at *magical* ... --- # Future of {flipbookr} ### flipbookr might feel magical w/ a chunk_reveal() modified behaivior for on-demand mini flipbooks from within live session (rmd/qmd). -- ### Using Dr. Kelly Bodwin's live chunk getting strategy as used in {flair}. https://github.com/EvaMaeRey/knitcodegetlive, (working) -- ### and rstudioapi::viewer... (not working) -- ### and maybe addin... (to be added). -- ### only getting started with .qmd (Dr. Kieran Healy) --- # Stats 101 classroom goal... ### New efforts to create `chunk_reveal_live` might put this tech in the hands of more coding newcomers; including on-the-fly classroom use. Arguably the people that might find flipbooks the most useful --- people who aren't going to be able to 'just-read' a pipeline of code --- might find them even more engaging when they are used to reviewing and presenting on the most interesting pipelines: their own explorations of their own data. --- count: false .panel1-stats_101-auto[ ```r *library(ggplot2) ``` ] .panel2-stats_101-auto[ ] --- count: false .panel1-stats_101-auto[ ```r library(ggplot2) *library(ggsmoothfit) # stat fit below ``` ] .panel2-stats_101-auto[ ] --- count: false .panel1-stats_101-auto[ ```r library(ggplot2) library(ggsmoothfit) # stat fit below *mtcars ``` ] .panel2-stats_101-auto[ ``` ## mpg cyl disp hp drat wt qsec vs am gear carb ## Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4 ## Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4 ## Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1 ## Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1 ## Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2 ## Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1 ## Duster 360 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4 ## Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2 ## Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2 ## Merc 280 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4 ## Merc 280C 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4 ## Merc 450SE 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3 ## Merc 450SL 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3 3 ## Merc 450SLC 15.2 8 275.8 180 3.07 3.780 18.00 0 0 3 3 ## Cadillac Fleetwood 10.4 8 472.0 205 2.93 5.250 17.98 0 0 3 4 ## Lincoln Continental 10.4 8 460.0 215 3.00 5.424 17.82 0 0 3 4 ## Chrysler Imperial 14.7 8 440.0 230 3.23 5.345 17.42 0 0 3 4 ## Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1 ## Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2 ## Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1 ## Toyota Corona 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1 ## Dodge Challenger 15.5 8 318.0 150 2.76 3.520 16.87 0 0 3 2 ## AMC Javelin 15.2 8 304.0 150 3.15 3.435 17.30 0 0 3 2 ## Camaro Z28 13.3 8 350.0 245 3.73 3.840 15.41 0 0 3 4 ## Pontiac Firebird 19.2 8 400.0 175 3.08 3.845 17.05 0 0 3 2 ## Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1 ## Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2 ## Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2 ## Ford Pantera L 15.8 8 351.0 264 4.22 3.170 14.50 0 1 5 4 ## Ferrari Dino 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6 ## Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8 ## Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2 ``` ] --- count: false .panel1-stats_101-auto[ ```r library(ggplot2) library(ggsmoothfit) # stat fit below mtcars %>% * ggplot() ``` ] .panel2-stats_101-auto[ <!-- --> ] --- count: false .panel1-stats_101-auto[ ```r library(ggplot2) library(ggsmoothfit) # stat fit below mtcars %>% ggplot() + * aes(x = wt) ``` ] .panel2-stats_101-auto[ <!-- --> ] --- count: false .panel1-stats_101-auto[ ```r library(ggplot2) library(ggsmoothfit) # stat fit below mtcars %>% ggplot() + aes(x = wt) + * aes(y = mpg) ``` ] .panel2-stats_101-auto[ <!-- --> ] --- count: false .panel1-stats_101-auto[ ```r library(ggplot2) library(ggsmoothfit) # stat fit below mtcars %>% ggplot() + aes(x = wt) + aes(y = mpg) + * geom_point() ``` ] .panel2-stats_101-auto[ <!-- --> ] --- count: false .panel1-stats_101-auto[ ```r library(ggplot2) library(ggsmoothfit) # stat fit below mtcars %>% ggplot() + aes(x = wt) + aes(y = mpg) + geom_point() + * geom_smooth(method = lm, se = F) ``` ] .panel2-stats_101-auto[ 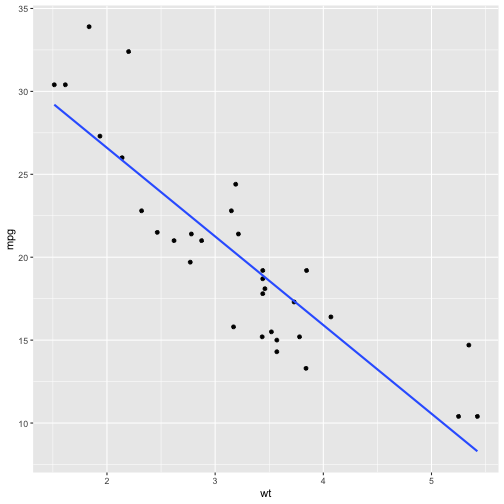<!-- --> ] --- count: false .panel1-stats_101-auto[ ```r library(ggplot2) library(ggsmoothfit) # stat fit below mtcars %>% ggplot() + aes(x = wt) + aes(y = mpg) + geom_point() + geom_smooth(method = lm, se = F) + * stat_fit(method = lm, * geom = "point", * color = "blue") ``` ] .panel2-stats_101-auto[ 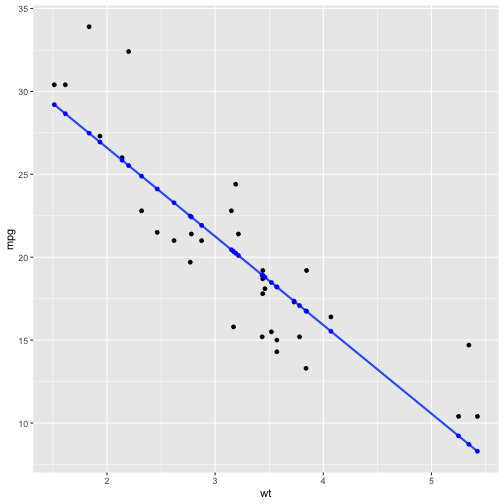<!-- --> ] --- count: false .panel1-stats_101-auto[ ```r library(ggplot2) library(ggsmoothfit) # stat fit below mtcars %>% ggplot() + aes(x = wt) + aes(y = mpg) + geom_point() + geom_smooth(method = lm, se = F) + stat_fit(method = lm, geom = "point", color = "blue") + * stat_fit(method = lm, * geom = "segment", * color = "red") ``` ] .panel2-stats_101-auto[ 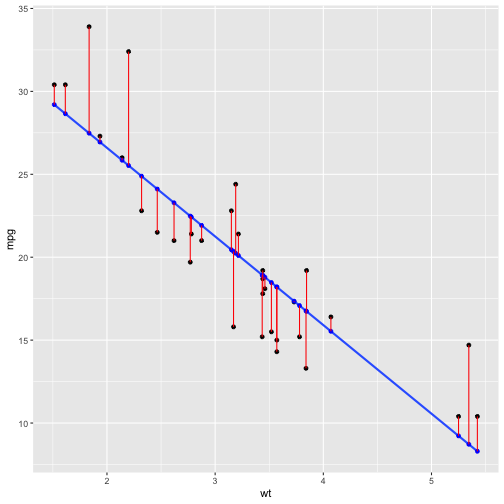<!-- --> ] --- count: false .panel1-stats_101-auto[ ```r library(ggplot2) library(ggsmoothfit) # stat fit below mtcars %>% ggplot() + aes(x = wt) + aes(y = mpg) + geom_point() + geom_smooth(method = lm, se = F) + stat_fit(method = lm, geom = "point", color = "blue") + stat_fit(method = lm, geom = "segment", color = "red") + * geom_smooth(method = lm) ``` ] .panel2-stats_101-auto[ 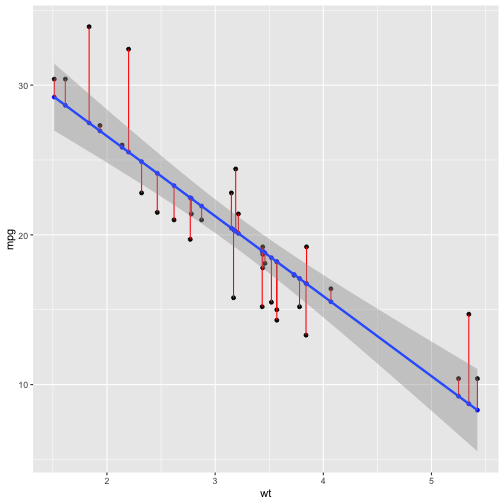<!-- --> ] <style> .panel1-stats_101-auto { color: black; width: 38.6060606060606%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel2-stats_101-auto { color: black; width: 59.3939393939394%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel3-stats_101-auto { color: black; width: NA%; hight: 33%; float: left; padding-left: 1%; font-size: 80% } </style> <!-- --- --> <!-- ## Flipbooks and proverb about learning --> <!-- ### Tell me and I forget. --> <!-- -- --> <!-- ### Show me, I remember. (creating flipbooks for others) --> <!-- -- --> <!-- ### Let me do and, I understand. (making flipbooks more accessible) --> <!-- --- --> <!-- ### Extending the proverb... --> <!-- ### Let me tell you about what I've done, I expose what I might not fully understand... --> <!-- -- --> <!-- (and then ask newcomers to talk you though *their* pipeline) --> <!-- ### Flipbooks I make myself, let me reflect on what I've done, --> <!-- -- --> <!-- in a step by step way. --> <!-- -- --> <!-- In a workshop or classroom setting, too, I can go through verbalizing with my peers & instructor about what I've done --> <!-- -- --> <!-- I understand more profoundly --> <!-- -- --> <!-- and my peers & instructor can help straighten out any misunderstandings. --> <!-- --- --> <!-- ## What'd be needed for the paper I want to publish. --> <!-- ## Data. --> <!-- -- --> <!-- Eyetracking data probably about how people are actually use and interact with flipbooks. --> <!-- --- -->